Implicit Attention using modified highway networks
Conceptual diagram
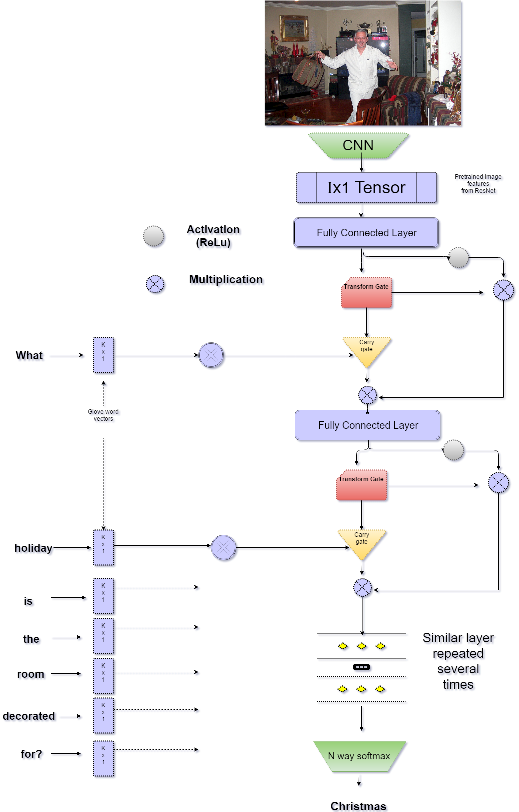
Extended Abstract
Abstract
We propose a version of highway network designed for the task of Visual Question Answering. We take inspiration from recent success of Residual Layer Network and Highway Network in learning deep representation of images and fine grained localization of objects. We propose variation in gating mechanism to allow incorporation of word embedding in the information highway. The gate parameters are influenced by the words in the question, which steers the network towards localized feature learning. This achieves the same effect as soft attention via recurrence but allows for faster training using optimized feed-forward techniques. We are able to obtain state-of-the-art1 results on VQA dataset for Open Ended and Multiple Choice tasks with current model.
Best Result
Open Ended
Overall Accuracy is: 62.73
Per Answer Type Accuracy is the following: other : 51.35 number : 38.07 yes/no : 82.58
Multiple Choice
Overall Accuracy is: 64.81
Per Answer Type Accuracy is the following: other : 55.82 number : 39.14 yes/no : 82.13
^ Open Ended employed statistical filtering, ie. for every question category (64 category types see VQA Paper by Agrawal et al) answers were choosen to be within 98% of the seen answers from the training set. This increased the accuracy of model by more than a percent. For Multiple Choice such filtering was not employed becuase it was expected to choose answers from the given 18 choices.
Features
Image
Words
Misc
Comparison of results from the VQA Challenge
- Detailed comparison of results will be published here, once VQA has completed evaluation of the challange.
Relevant Papers
- Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. “End-to-end memory networks.” Advances in Neural Information Processing Systems. 2015.
- Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
- Srivastava, Rupesh Kumar, Klaus Greff, and Jürgen Schmidhuber. “Highway networks.” arXiv preprint arXiv:1505.00387 (2015).
- Glorot, Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” International conference on artificial intelligence and statistics. 2010.
- He, Kaiming, et al. “Deep Residual Learning for Image Recognition.” arXiv preprint arXiv:1512.03385 (2015).
- For papers related to VQA see Literature Survey
Old apporach using end-to-end attention with skip-thought
- Our Approach
- Use of visual attention model along with end-to-end memory networks which are trained on skip-thought vectors on question tokens, and GoogLeNet dense layer image features.
- We are experimenting with application of Neural Turing Machines. We believe having a persistent memory will lead to sharing of knowledge between images where similar questions were asked.
- We are also experimenting to see if having spatial information could be useful in answering questions about location and direction. I am coding adaptation of CRF-RNN to extract spatial knowledge to be merged with image features.
- Literature Survey - (Almost) exhaustive list of papers tackling the problem and their results and their methodologies, includes survey of techniques and tricks used by various research groups.
- Visual Question Answering Demo - A ipython notebook demonstration of a simple but yet effective mode for visual question answering inference.
- Github Code of simple demo - Code of the aforementioned demo. Also includes standalone code to run inference on a server with pretrained models and weights.
- Visual Question Answering Notes - contains basic modules and ideas that I am experimenting with.
- Visual Comparision of Results
- This a large file ! Load at your risk.
- Images are not loaded but a link is provided.
- This a large file ! Load at your risk.
- Obvious negative corrleation between confidence of Amazon Mechanical Turks and the accuracy of the system
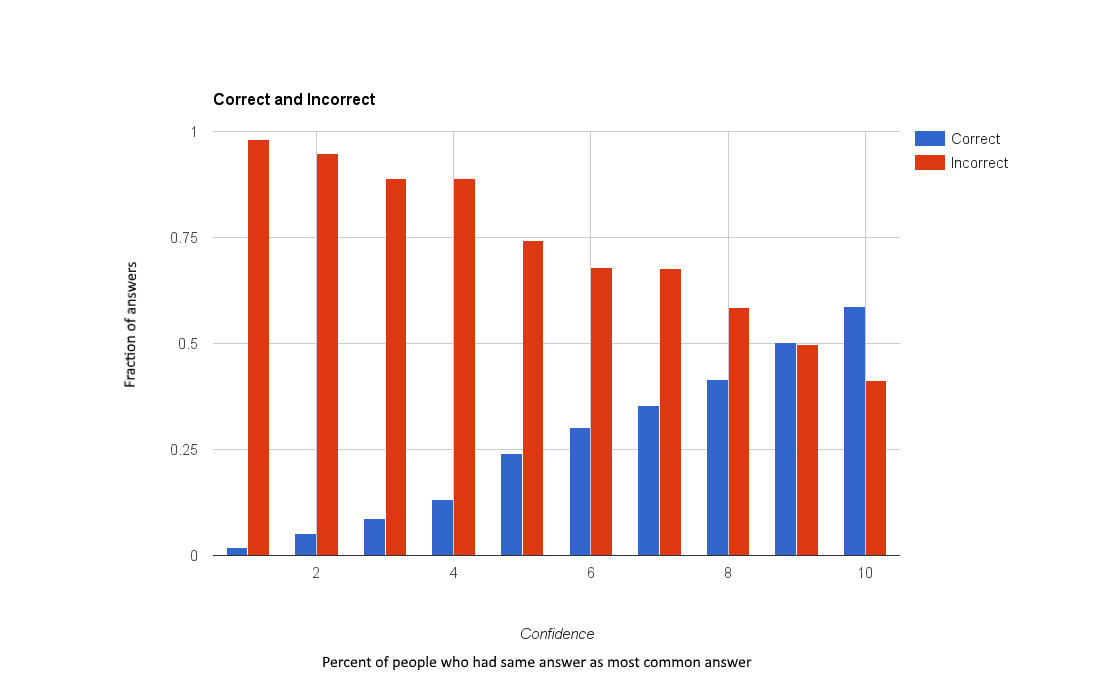
- Temporary Results
| Method | All | Y/N | Other | Num | Test-Std[All] |
|---|---|---|---|---|---|
| ~~~~~~~~~~~~~~ | ~~~~~~~~~~~~~ | ~~~~~~~~~~~~ | ~~~~~~~~~ | ~~~~~~~~~~ | ~~~~~~~~ |
| Image | 28.1 | 64.0 | 3.8 | 0.4 | - |
| Question | 48.1 | 75.7 | 27.1 | 36.7 | - |
| Q+I | 52.6 | 75.6 | 37.4 | 33.7 | - |
| LSTM Q+I | 53.7 | 78.9 | 36.4 | 35.2 | 54.1 |
| [16CMV] | 52.6 | 78.3 | 35.9 | 34.4 | - |
| [09AMA] | 55.7 | 79.2 | 40.1 | 36.1 | 56.0 |
| [13BOW] | 55.7 | 76.5 | 42.6 | 35.0 | 55.9 |
| [07DPP] | 57.2 | 80.7 | 41.7 | 37.2 | 57.4 |
| [17LCN] | 57.9 | 80.5 | 43.1 | 37.4 | 58.0 |
| [11AAA] | 57.9 | 80.8 | 43.2 | 37.3 | 58.2 |
| [12SAN] | 58.7 | 79.3 | 46.1 | 36.6 | 58.9 |
| [15DMN] | 60.3 | 80.5 | 48.3 | 36.8 | 60.4 |
| OUR | 60.4 | 81.5 | 47.6 | 37.2 | 60.7 |
-
Comparison of results from different models
Number of unique answers / total number of models == total questions with those unique answers / Total questions % percentage of questions with those number of unique answers
ALL QUESTION
————————
1/9 == 18073/60864 % 0.297
2/9 == 23593/60864 % 0.388
3/9 == 09611/60864 % 0.158
4/9 == 06378/60864 % 0.105
5/9 == 02557/60864 % 0.042
6/9 == 00593/60864 % 0.01
7/9 == 00059/60864 % 0.001Filtered QUESTION (NO Binary decision questions)
————————
1/9 == 06438/60864 % 0.106
2/9 == 10172/60864 % 0.167
3/9 == 09136/60864 % 0.15
4/9 == 05566/60864 % 0.091
5/9 == 02121/60864 % 0.035
6/9 == 00500/60864 % 0.008
7/9 == 00054/60864 % 0.001 -
Detailed Analysis of the different Visual Question Answering models
- Memory
- Attention models vs non-attention models
- LSTM vs GRU
- Episodic memory vs Semantic memory
- No bidirectinal LSTM
- Activation functions used
- Choice of Activations
- Use of Batch Normalization
VQA Dataset
(as self-published by authors- not verified)
Results below are for testdev-2015, except the final column which is for test-standard
| Method | All | Y/N | Other | Num | Test-Std[All] |
|---|---|---|---|---|---|
| ~~~~~~~~~~~~~~ | ~~~~~~~~~~~~~ | ~~~~~~~~~~~~ | ~~~~~~~~~ | ~~~~~~~~~~ | ~~~~~~~~ |
| Image | 28.1 | 64.0 | 3.8 | 0.4 | - |
| Question | 48.1 | 75.7 | 27.1 | 36.7 | - |
| Q+I | 52.6 | 75.6 | 37.4 | 33.7 | - |
| LSTM Q+I | 53.7 | 78.9 | 36.4 | 35.2 | 54.1 |
| [16CMV] | 52.6 | 78.3 | 35.9 | 34.4 | - |
| [09AMA] | 55.7 | 79.2 | 40.1 | 36.1 | 56.0 |
| [13BOW] | 55.7 | 76.5 | 42.6 | 35.0 | 55.9 |
| [07DPP] | 57.2 | 80.7 | 41.7 | 37.2 | 57.4 |
| [17LCN] | 57.9 | 80.5 | 43.1 | 37.4 | 58.0 |
| [11AAA] | 57.9 | 80.8 | 43.2 | 37.3 | 58.2 |
| [12SAN] | 58.7 | 79.3 | 46.1 | 36.6 | 58.9 |
| [15DMN] | 60.3 | 80.5 | 48.3 | 36.8 | 60.4 |
| OUR | 60.4 | 81.5 | 47.6 | 37.2 | 60.7 |
List of papers
- [01VQA] VQA: Visual Question Answering
- [02EMD] Exploring Models and Data for Image Question Answering
- [03LAQ] Learning to Answer Questions From Image Using Convolutional Neural Network
- [04DCQ] Deep Compositional Question Answering with Neural Module Networks
- [05ABC] An attention based convolutional neural network for visual question answering
- [06ATM] Are you talking to a machine? datasetand methods for multilingual image question answering
- [07DPP] Image question answering using convolutional neural networkwith dynamic parameter prediction
- [08WTL] Where to look: Focus regions for visual question answering
- [09AMA] Ask me anything: Free-form visual question answering based on knowledge from external sources
- [10V7W] Visual7W: Grounded Question Answering in Images
- [11AAA] Ask, Attend and Answer: Exploring question-guided spatial attention for visual question answering
- [12SAN] Stacked attention networks for image questionanswering
- [13BOW] Simple Baseline for Visual Question Answering
- [14ICV] Image Captioning & Visual Question Answering Based on Attributes & External Knowledge
- [15DMN] Dynamic Memory Networks for Visual and Textual Question Answering
- [16CMV] Compositional Memory for Visual Question Answering
- [17LCN] Learning to Compose Neural Networks for Question Answering