Literature Survey
- A Review of Learning Vector Quantization Classifiers
-
[PDF] Nova, David, and Pablo A. Estévez. “A review of learning vector quantization classifiers.” Neural Computing and Applications 25.3-4 (2014): 511-524.
-
Abstract
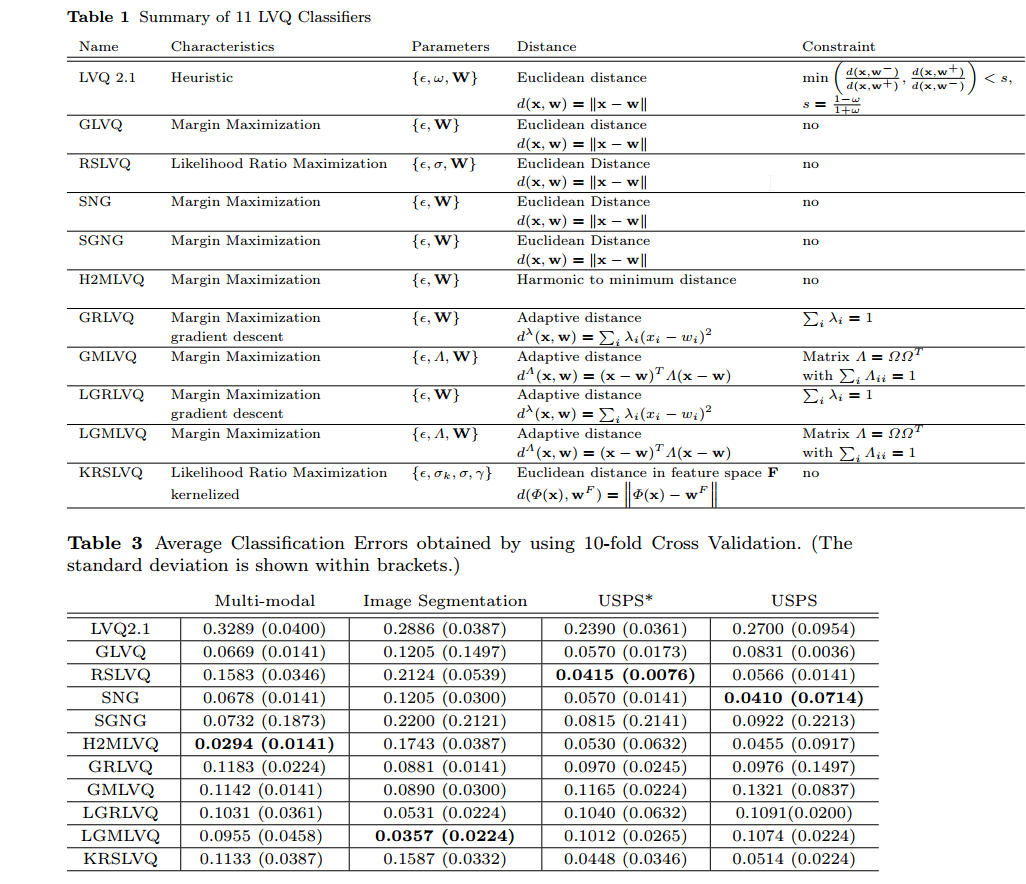
In this work we present a review of the state of the art of Learning Vector Quantization (LVQ) classifiers. A taxonomy is proposed which integrates the most relevant LVQ approaches to date. The main concepts associated with modern LVQ approaches are defined. A comparison is made among eleven LVQ classifiers using one real-world and two artificial datasets.
-
Conclusion
We have presented a review of the most relevant LVQ classifiers developed in the last 25 years. We introduced a taxonomy of LVQ classifiers as a general framework. Two different main cost functions have been proposed in the literature: margin maximization and likelihood ratio maximization. LVQ classifiers based on margin maximization have been demonstrated to have good performance in many problems. These methods put the prototypes in the centroid of the data which makes them less flexible with overlapping data.
The experiments done in this work have shown that there is no free lunch; each method has its own pros and cons. The different LVQ methods were designed for dealing with specific problems and datasets. From a more general point of view, LVQ classifiers have been demonstrated to be very competitive classifiers, and further research is needed to achieve the greatest success in pattern recognition tasks.
- Vector Quantization for Machine Vision
-
[PDF] Liguori, Vincenzo. “Vector Quantization for Machine Vision.” arXiv preprint arXiv:1603.09037 (2016).
-
Abstract
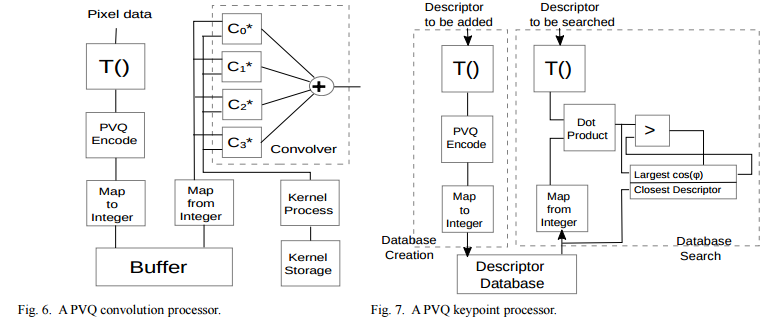
This paper shows how to reduce the computational cost for a variety of common machine vision tasks by operating directly in the compressed domain, particularly in the context of hardware acceleration. Pyramid Vector Quantization (PVQ) is the compression technique of choice and its properties are exploited to simplify Support Vector Machines (SVM), Convolutional Neural Networks(CNNs), Histogram of Oriented Gradients (HOG) features, interest points matching and other algorithms.
-
Conclusion
This paper proposes to use PVQ to speed up some well known machine vision algorithms. Future work will include testing of the ideas presented and, if successful, the design of specialized hardware demonstrating the technology. Particularly interesting is the question of whether this methodology can be applied to simplify the computation of deeper layers of CNNs. However, it is clear that any algorithm that makes use of dot products, especially on sparse data, could take advantage of this framework and the use of PVQ encoding should be investigated. This could include algorithms in fields unrelated to machine vision such as Natural Language Processing which makes use of cosine vector similarity.
- Compressing Deep Convolutional Networks using Vector Quantization
-
[PDF] Gong, Yunchao, et al. “Compressing deep convolutional networks using vector quantization.” arXiv preprint arXiv:1412.6115 (2014).
-
Abstract
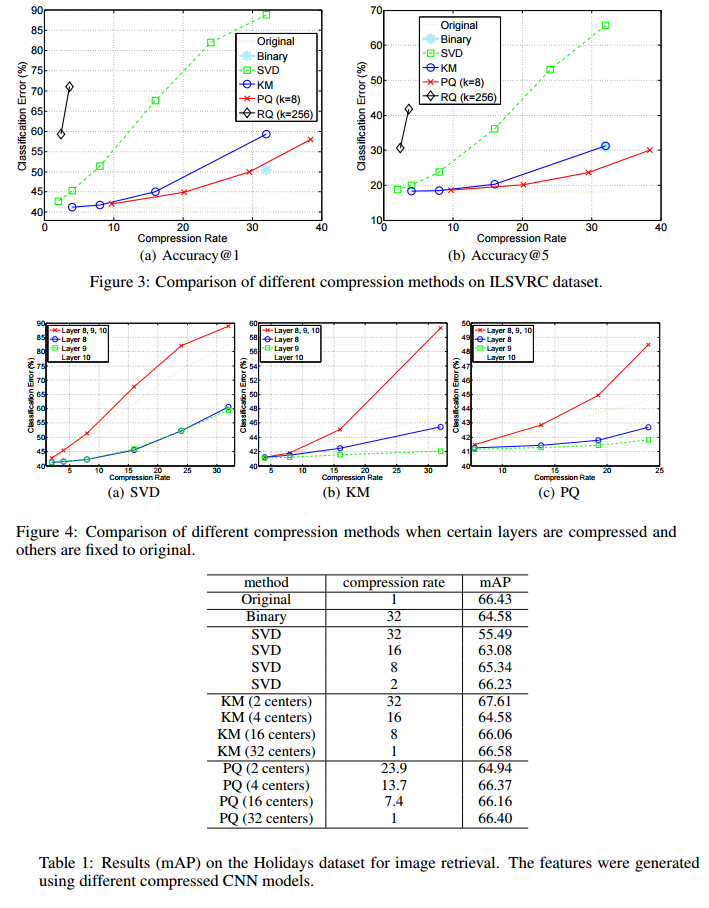
Deep convolutional neural networks (CNN) has become the most promising method for object recognition, repeatedly demonstrating record breaking results for image classification and object detection in recent years. However, a very deep CNN generally involves many layers with millions of parameters, making the storage of the network model to be extremely large. This prohibits the usage of deep CNNs on resource limited hardware, especially cell phones or other embedded devices. In this paper, we tackle this model storage issue by investigating information theoretical vector quantization methods for compressing the parameters of CNNs. In particular, we have found in terms of compressing the most storage demanding dense connected layers, vector quantization methods have a clear gain over existing matrix factorization methods. Simply applying k-means clustering to the weights or conducting product quantization can lead to a very good balance between model size and recognition accuracy. For the 1000-category classification task in the ImageNet challenge, we are able to achieve 16-24 times compression of the network with only 1% loss of classification accuracy using the state-of-the-art CNN.
-
Conclusion
We have addressed the storage problem of applying vector quantization to compress deep convolutional neural networks in embedded systems. Our work systematically studied how to compress the 108 parameters of a deep convolutional neural network, in order to save storage of the models. Unlike previous approaches that considered using matrix factorization methods, we proposed to study a series of vector quantization methods for compressing the parameters values using kmeans, we were able to obtain 8-16 compression rate of the parameters without sacrificing top-five accuracy in more than 0.5% of the compressions. In addition, by using structured quantization methods, we were able to further compress the parameters up to 24 times while keeping the loss of top-five accuracy within 1%.
Somewhat surprisingly, we found that by simply performing a scalar quantization to the parameteri. By compressing the parameters more than 20 times, we addressed the problem of applying state-of-the art CNNs in embedded devices. Given a state-of-the-art model with about 200MB of parameters, we were able to reduce them to less than 10MB, which enabled us to easily deploy such models. Another interesting implication of this paper is that our empirical results confirmed the finding in Denil et al. (2013) that the useful parameters in a CNN are about 5% (we were able to compress them about 20 times).
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
-
[PDF] Han, Song, Huizi Mao, and William J. Dally. “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding.” arXiv preprint arXiv:1510.00149 (2015).
-
Abstract
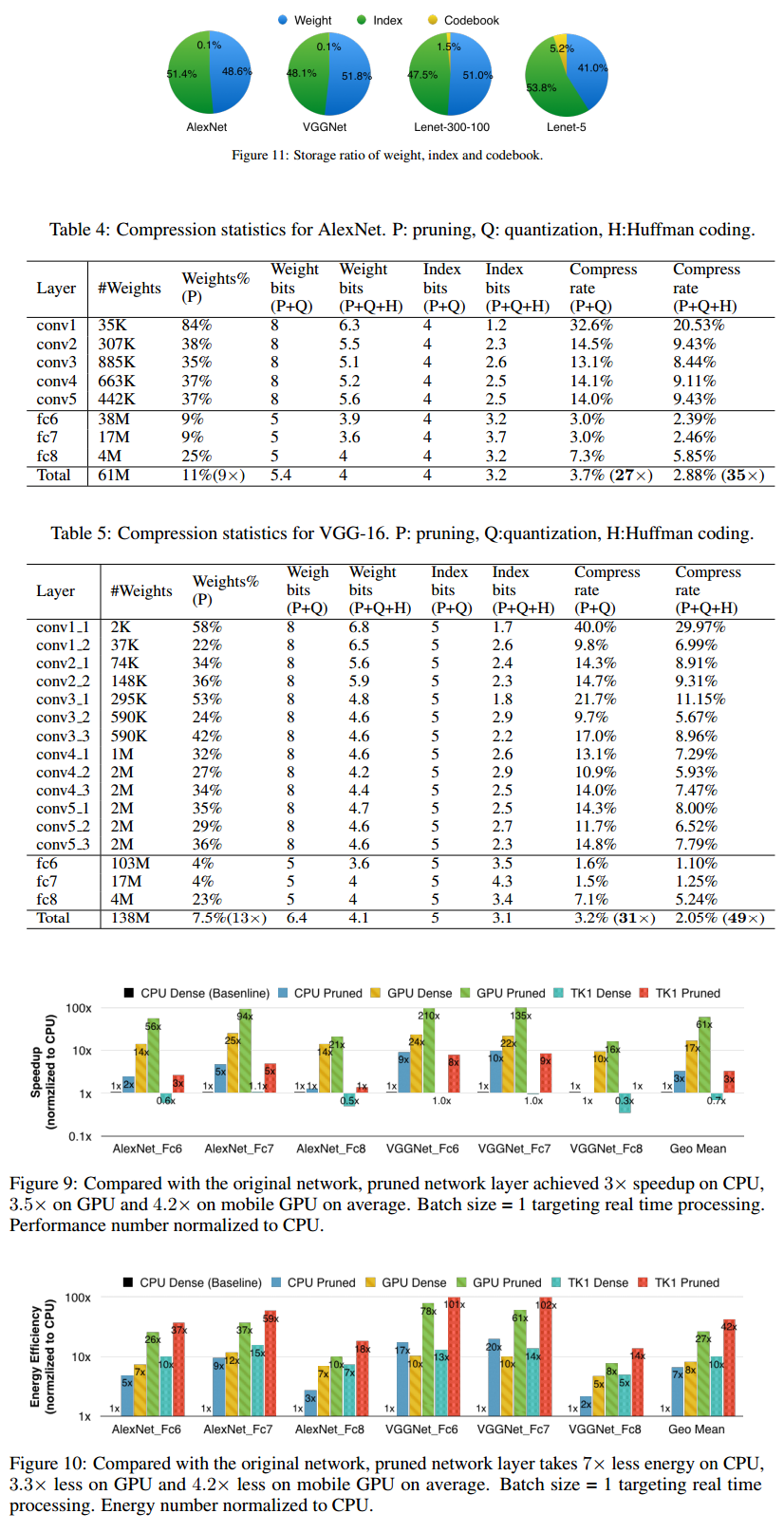
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources. To address this limitation, we introduce “deep compression”, a three stage pipeline: pruning, trained quantization and Huffman coding, that work together to reduce the storage requirement of neural networks by 35x to 49x without affecting their accuracy. Our method first prunes the network by learning only the important connections. Next, we quantize the weights to enforce weight sharing, finally, we apply Huffman coding. After the first two steps we retrain the network to fine tune the remaining connections and the quantized centroids. Pruning, reduces the number of connections by 9x to 13x; Quantization then reduces the number of bits that represent each connection from 32 to 5. On the ImageNet dataset, our method reduced the storage required by AlexNet by 35x, from 240MB to 6.9MB, without loss of accuracy. Our method reduced the size of VGG-16 by 49x from 552MB to 11.3MB, again with no loss of accuracy. This allows fitting the model into on-chip SRAM cache rather than off-chip DRAM memory. Our compression method also facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained. Benchmarked on CPU, GPU and mobile GPU, compressed network has 3x to 4x layerwise speedup and 3x to 7x better energy efficiency.
-
Conclusion
We have presented “Deep Compression” that compressed neural networks without affecting accuracy. Our method operates by pruning the unimportant connections, quantizing the network using weight sharing, and then applying Huffman coding. We highlight our experiments on AlexNet which reduced the weight storage by 35× without loss of accuracy. We show similar results for VGG-16 and LeNet networks compressed by 49× and 39× without loss of accuracy. This leads to smaller storage requirement of putting convnets into mobile app. After Deep Compression the size of these networks fit into on-chip SRAM cache (5pJ/access) rather than requiring off-chip DRAM memory (640pJ/access). This potentially makes deep neural networks more energy efficient to run on mobile. Our compression method also facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained.